Prédiction de la consommation électrique nationale
Une solution d'IA prédisant la consommation électrique journalière de la France (en MW), du notebook d'exploration jusqu'à une API REST en production sur le cloud, avec ré-entraînement automatisé, monitoring et détection de dérive. Un projet MLOps complet : pas seulement un modèle, mais toute la chaîne qui le rend fiable et maintenable dans le temps.
Le problème
Anticiper la consommation électrique est un enjeu critique pour l'équilibrage du réseau. À partir des données publiques RTE éco2mix (2012-2024), j'ai construit un modèle capable de prédire la consommation moyenne d'une journée à partir de la seule date, en exploitant la saisonnalité, les cycles hebdomadaires, les jours fériés et l'historique récent.
Démarche Data Science
Côté données, 15 features construites : encodage cyclique (mois, jour de l'année, jour de la semaine en sin/cos), week-end, jours fériés français, lags (J-1, J-7, J-30, J-365) et moyennes glissantes (7 et 30 jours).
Sept approches comparées sur un découpage strictement temporel (train 2013-2021 / validation 2022 / test 2023-2024), toutes tracées dans MLflow pour une comparaison reproductible et auditable :
MAPE de test par modèle : plus court, mieux c'est
Résultats sur la période de test
Sur les 731 jours jamais vus (2023-2024), la prédiction épouse la consommation réelle, pic hivernal comme creux estival, pour un MAPE de 2,37 %. Moyennes mensuelles, en gigawatts moyens par jour :
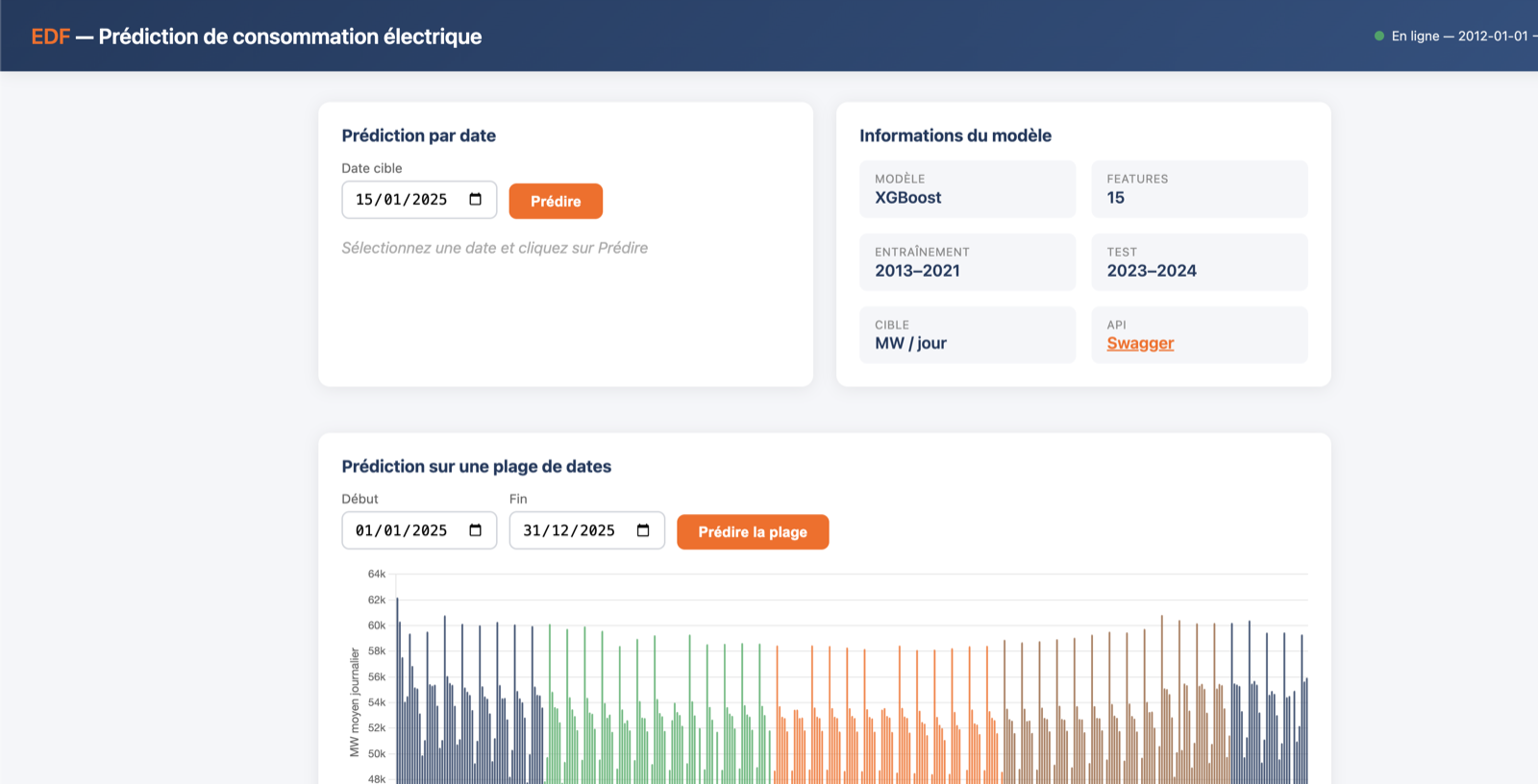
Mise en production : le cœur du projet
- API REST FastAPI : endpoints de prédiction (date unique, plage jusqu'à 365 jours), d'exploitation (
/health,/system, suivi de la qualité dans le temps), auth optionnelle par clé d'API, doc Swagger auto-générée. - Docker : image allégée dédiée à l'API (sans Keras/TensorFlow) pour tenir sur une petite instance ;
docker-composeorchestrant API + MLflow + Prometheus. - Déploiement AWS EC2 (t3.micro, eu-west-3) : 1 worker uvicorn, swap, IP fixe (Elastic IP), HTTPS via reverse proxy Caddy (Let's Encrypt). Pipeline de données sur S3 via rôle IAM d'instance, aucune clé statique.
Le pipeline GitLab CI/CD couvre tout le cycle de vie, ré-entraînement quotidien inclus, avec mise en prod conditionnée à un seuil de qualité (MAPE < 3 %) :
Maintenabilité & monitoring
- Détection de data drift via le PSI (Population Stability Index), rapport JSON archivé, branché en CI en mode alerting.
- Observabilité Prometheus : latence, volumétrie, codes HTTP par endpoint, métriques métier et système (RAM/CPU).
- Tests automatisés : smoke tests de l'API + test de charge Locust ; manifests Kubernetes (HPA) pour démontrer une cible scalable.
- Conformité RGPD documentée et exposée (
/rgpd) : aucune donnée personnelle (open data + variables calendaires).
Chaque ré-entraînement mensuel est tracé : le MAPE de test reste stable bien sous le seuil de mise en prod (3 %), condition de promotion automatique du modèle :
6 ré-entraînements automatisés : MAPE de test dans le temps
La détection compare la distribution de référence (2012-2021) à l'année courante via le PSI. En 2024, toutes les variables franchissent le seuil d'alerte (0,25) : la consommation a structurellement baissé (crise énergétique de 2022, sobriété). C'est précisément ce signal qui déclenche l'alerte et légitime le ré-entraînement automatique.
PSI par variable : < 0,10 stable, 0,10 à 0,25 modéré, > 0,25 élevé
En production, pour de vrai
Au-delà des graphiques ci-dessus, la solution tourne réellement sur le cloud. Quelques captures de la stack en fonctionnement :


Ce que ce projet démontre
La maîtrise du cycle de vie complet d'un modèle (données → modèle → API → cloud → monitoring → ré-entraînement) et un sens de l'ingénierie sous contrainte réelle : faire tourner toute une stack sur une instance à 1 Go de RAM, optimiser l'image Docker, sécuriser les accès cloud sans clés statiques. Le projet a aussi été piloté en mode agile (Scrum/Kanban, backlog, KPIs) avec des livrables formels (cadrage, plan de tests, runbook).